Peter van Willenswaard on PASC
How can two channels of 16-bit audio be recorded on something similar to an analog cassette? The maximum bit rate in a linear track of a tape running at 4.76cm/s (standard compact cassette speed) is somewhere near 100kbit/s which, as DCC offers eight parallel tracks, results in a total "space" of 768kb/s. Half of that space is consumed by Reed/Solomon interleaving, synchronization bits, and a 10:8 modulation scheme, so only 384kb/s are available for pure audio information. Now there is no way around Shannon/Nyquist, so in order to maintain 20kHz of audio bandwidth, sampling must be at slightly over 40kHz. (DCC supports both 44.1 and 48kHz sampling, but will also accept 32kHz-sampled digital broadcast.) 48 kilosamples/s and 384kb/s bit rate comes down to an average of 8 bits per sample for the stereo signal, so an average of 4 bits per sample remains for one channel. It all just had to fit in there to make DCC work as a digital successor to the conventional compact cassette! But how on earth...?
PASC
The answer developed by Philips is called Precision Adaptive Sub-band Coding, PASC. It is not an advanced form of data compression as used with computers or datalinks. Now traditional PCM systems try to create a total and near-perfect (given the limitations set by 16-bit linear coding) digital representation of the sound the microphone received. But PASC takes its point of reference at the other end of the chain: at the ear. The rule for PASC is to calculate what is audible and encode only that information, in a very efficient notation. Once it has done that, it reorganizes the digital information in such a way that it occupies the available space in an optimal manner (reallocation). Let us follow this process in more detail. First the audio band is divided into 32 sub-bands. Surprisingly, these sub-bands do not follow a critical band topology (well known from certain theories modeling human hearing); they are all equally wide, roughly 700Hz each. DSP technology is now so advanced that (in the digital domain) it is possible to split the audio band into sub-bands and recombine them with a perfect result, without any time-domain or frequency-response errors (footnote 6). That is, with sheer unlimited computing capacity, in a lab. Implementation in a real-world chip is another matter; while Philips thinks that they have come far enough now to face the world, they feel even further improvements may be possible in the future.
Threshold of hearing and masking
The next step is performed in each frequency sub-band. The minimum loudness a signal must have to be at all detectable by the human ear is a function of frequency (fig.3). This means that in each sub-band a certain threshold level can be defined and any information below that threshold can be discarded.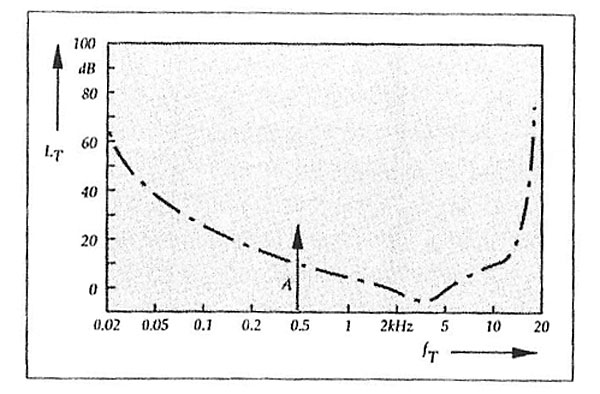
 Be aware that sampling theory isn't primarily concerned with frequency but with bandwidth. Once the audio band has been divided up into 32 sub-bands of approximately 600Hz wide, during processing the sample frequency with which each band is scanned need only be a little over 1200Hz. So despite the fact that quite a number of bands have to be looked into simultaneously, the total amount of data remains the same as for an undivided audio band. But there is no gain in efficiency here either.
Scale and mantissa
Be aware that sampling theory isn't primarily concerned with frequency but with bandwidth. Once the audio band has been divided up into 32 sub-bands of approximately 600Hz wide, during processing the sample frequency with which each band is scanned need only be a little over 1200Hz. So despite the fact that quite a number of bands have to be looked into simultaneously, the total amount of data remains the same as for an undivided audio band. But there is no gain in efficiency here either.
Scale and mantissa
The next step is amplitude description of what remains above the threshold in each sub-band. Unlike PCM media, which use 16-bit linear quantizing, PASC uses a floating-point notation with a mantissa and a scale factor. The mantissa defines the resolution, and the scale shifts the reference point for the mantissa up or down the dynamic range. The mantissa is basically 15 bits long, but PASC may choose a shorter mantissa if it decides that there is no need for a full 15-bit word length, for signals near the noise floor, for example, or the threshold. The scale factor isn't simply linear along the dynamic range axis, but has been given a non-linearity which reflects the behavior of the ear in this respect. The ear doesn't care if a sound is exactly 118 or 120dB spl—both are almost painfully loud—but at the other end of the dynamic range a 2dB step would be coarse, as the ear is quite sensitive to such subtleties when dealing with quiet sounds. The maximum mantissa length of 15 bits is reflected in the (theoretical) THD+N figure quoted for DCC: –92dB, which is 1 bit or 6dB above the –98dB of CD. But in the CD format there is no scale factor and therefore the THD+N floor remains at a constant absolute level; a –20dB signal will see its THD+N 78dB down. In DCC, because of the floating-point amplitude description, THD+N will remain 92dB below the signal until the system noise floor is reached. Philips quotes a 108dB dynamic range for DCC (where CD, or R-DAT for that matter, can never go beyond 98dB). Using floating-point notation instead of linear coding means another gain in efficiency. By the way, all internal computation in PASC takes place in a 24-bit–wide processor.
In the Philips literature the range controlled by the scale factor is described as 124dB. As mentioned, the mantissa can cover 92dB. One would be tempted to simply add these figures to find a total dynamic range of 216dB. That would be false because, as explained, the scale factor is of non-linear character. The consequence of that is that a mantissa bit at high-scale values is larger in voltage terms than at low-scale values. The scale must be seen as a multiplication factor. Because of the non-linear scale, the 15-bit mantissa will span 92dB at the top of the range but less and less as the scale factor zooms in at softer sounds (still using 15, but effectively smaller, bits). Philips claims that scale and mantissa together realize a potential resolution considerably beyond the –146dB noise floor set by the 24-bit–wide words used by the internal processor. The real bottleneck is in the A/D converter, which necessarily precedes all PASC (digital!) processing; the best converters to date won't give you more than 18 or 19 bits of reliable audio information.
The quoted dynamic range (108dB) is the wide-band noise-floor figure normally measured with a –60dB signal; ideally, one would find THD+N at –48dB; adding the remaining 60dB "headroom" then results in 108dB dynamic range.
Bits of reallocation
One of the nicer properties of most sounds and music is that their content changes continuously. Which means that not all space in all 32 sub-bands would be fully in use; many might even be completely empty (above the threshold) from time to time. There is a certain coding space reserved for each of the 32 sub-bands. A temporarily not-so-busy sub-band thus wouldn't use all of its space, which would be a waste of efficiency. So PASC reallocates information from the busier sub-bands to empty or not-so-busy sub-bands (along with some address code for suitable re-reallocation at decoding to enable proper reconstruction).
It would be interesting to find out what happens if the system should come near or into overload (ie, all 32 sub-bands in full-orchestra climax). In view of the intelligence with which PASC goes to work, any hard overload phenomenon (clipping type) would seem unlikely. Instead, a temporary loss of detail would seem logical. Philips spokesman Gerry Wirtz explained that this is exactly what happens, but, as the ear will be overloaded in the same way (all the loud sound masking the quieter details), there won't be any audible degradation. He added that PASC's capabilities in this respect are equal to or better than the ear's, and that it is in fact much easier to correctly encode loud musical passages than soft ones.
The gain in efficiency resulting from this kind of signal processing surprised even the Philips people: from 16 bits per channel needed in linear PCM to 4 bits average per channel in PASC. Don't be tempted to think of such 4-bit codes as 4-bit samples containing amplitude data, because you'd miss the point entirely! The 4-bit code is a lot smarter than simply an amplitude representation. The 4-bit "samples" should rather be seen as pieces of a dynamically varying jigsaw puzzle that is to be solved by the decoder. It would seem as though the decoder would have to be a very intelligent piece of equipment, but that isn't the case either. The intelligence is in the code! It is the code itself that contains coding keys and reallocation keys; these keys have become part of a data stream consisting of 4-bit codes (footnote 8). Indeed it would have been an unnecessary limitation (and probably even impossible) to locate these keys in a ROM near the decoder because each sound is different, requiring its own unique PASC coding. (It seems unlikely that all routing, "key," information for the decoder could be added to a single 8-bit stereo sample that also contains full audio information; therefore it must be assumed that certain "handling instructions" are spread over a group of samples.)
The keys in the 4-bit codes tell the decoding computer what to do, how to reallocate what from where and where to, which scaling has been used for that sample, and what the mantissa looked like. The decoding computer just follows orders; it's the code that's intelligent. Therefore the decoding computer will decode not only DCC signals but any signal within the same family: DAB signals, for instance (Philips is taking part in Digital Audio Broadcasting experiments sponsored by the European Community's Star Wars counterpart, the Eureka project), or a lower-quality 2-bit signal if necessary; it could make th
e switch from one sample to the next if need be, because it isn't the decoder switching but the code giving different instructions.
Digital audio revolution
If PASC does what it promises and literally discards only what could never be heard anyway, we're in for a revolution in both professional and consumer digital audio. It may be too early for specific speculations, but a host of possibilities passes the mind's eye. One of the limitations in digital audio has always been data storage; a higher basic sampling frequency or more amplitude bits would unavoidably consume a lot more space. PASC helps out here with a considerable reduction in data rate, a factor of four. One thing is clear in my opinion: if PASC works, there's no future for PCM in audio (footnote 9).—Peter van Willenswaard
Footnote 6: A good overview of the material is given by Vaidaynathan in IEEE Proceedings, January 1990, pp.56–93.—Peter van Willenswaard
Footnote 7: A CD prepared by the Institute for Perception Research (IPO) of Eindhoven Technical University and supported by the ASA demonstrates these effects. This CD can be obtained from DB Systems, Main Street, Rindge Center, NH.—Peter van Willenswaard
Footnote 8: The real situation is slightly different, but I preferred to keep this out of the main story to avoid unnecessary complications. PASC doesn't treat the stereo signal as two mono signals, but takes stereophonic channel correlation into account. This means that inside DCC there are no longer 4-bit codes referring to L- and R-channel information, but only 8-bit stereo codes. The input condition of two independent channels is said to be completely restored at the output after decoding. Philips's Gerry Wirtz added that this stereo-coding has not been an easy thing to get right (main problem: stability of the stereo image).—Peter van Willenswaard
Footnote 9: I'm not so sure. For original master recording, it will probably always be necessary to have the analog signal described exactly, as with a PCM system. One can then postpone the decision how to process the hard digital data for a consumer medium until a later date, reserving the right to second-guess that decision if necessary.—John Atkinson
The answer developed by Philips is called Precision Adaptive Sub-band Coding, PASC. It is not an advanced form of data compression as used with computers or datalinks. Now traditional PCM systems try to create a total and near-perfect (given the limitations set by 16-bit linear coding) digital representation of the sound the microphone received. But PASC takes its point of reference at the other end of the chain: at the ear. The rule for PASC is to calculate what is audible and encode only that information, in a very efficient notation. Once it has done that, it reorganizes the digital information in such a way that it occupies the available space in an optimal manner (reallocation). Let us follow this process in more detail. First the audio band is divided into 32 sub-bands. Surprisingly, these sub-bands do not follow a critical band topology (well known from certain theories modeling human hearing); they are all equally wide, roughly 700Hz each. DSP technology is now so advanced that (in the digital domain) it is possible to split the audio band into sub-bands and recombine them with a perfect result, without any time-domain or frequency-response errors (footnote 6). That is, with sheer unlimited computing capacity, in a lab. Implementation in a real-world chip is another matter; while Philips thinks that they have come far enough now to face the world, they feel even further improvements may be possible in the future.
The next step is performed in each frequency sub-band. The minimum loudness a signal must have to be at all detectable by the human ear is a function of frequency (fig.3). This means that in each sub-band a certain threshold level can be defined and any information below that threshold can be discarded.
Fig.3 The dash-dot curve represents the manner in which the threshold of human hearing senstivity changes with frequency. Any tones softer than the curve will not be heard. The tone A, represented by the arrow, though very soft, will be audible when it is on its own,
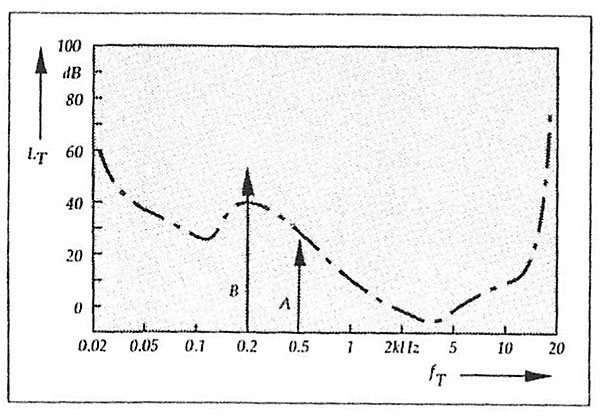
A second threshold phenomenon is masking. It is well known from research into human auditory perception under which conditions a strong frequency component will mask a nearby weaker one. A strong component will modify the threshold curve near its own frequency (more so above than below), thereby rendering nearby weaker components inaudible (fig.4). You can hear a pen drop on the carpet in a silent room; you can't during a noisy party in that same room. A different kind of masking, equally well documented, occurs in the time domain: a loud signal preceding a softer one by a few milliseconds can mask that softer one. Even the reverse case applies: a soft sound preceding a louder may be masked by the louder one. If masking occurs, it depends on the difference in loudness and the distance in time, of course (footnote 7).
Fig.4 The presence of a louder sound at a lower frequency (B) increases the local threshold level to an extent that the soft sound (A) can no longer be heard. Since A no longer needs to be recorded, therefore, extra information capacity is released for more precise coding of B.
As the sound is registered, the signal processor adapts the various thresholds in each sub-band according to the signal energy in that sub-band. The thresholds aren't static, but dynamically follow the signal content. This leads to a higher coding efficiency, as only what is above the threshold (ie, what can be heard) is kept for coding.
It remains to be seen if PASC processing and coding take place on a strictly sample-to-sample basis. Gerry Wirtz of Philips refused to give conclusive answers here. My guess would be that this is not the case.
The next step is amplitude description of what remains above the threshold in each sub-band. Unlike PCM media, which use 16-bit linear quantizing, PASC uses a floating-point notation with a mantissa and a scale factor. The mantissa defines the resolution, and the scale shifts the reference point for the mantissa up or down the dynamic range. The mantissa is basically 15 bits long, but PASC may choose a shorter mantissa if it decides that there is no need for a full 15-bit word length, for signals near the noise floor, for example, or the threshold. The scale factor isn't simply linear along the dynamic range axis, but has been given a non-linearity which reflects the behavior of the ear in this respect. The ear doesn't care if a sound is exactly 118 or 120dB spl—both are almost painfully loud—but at the other end of the dynamic range a 2dB step would be coarse, as the ear is quite sensitive to such subtleties when dealing with quiet sounds. The maximum mantissa length of 15 bits is reflected in the (theoretical) THD+N figure quoted for DCC: –92dB, which is 1 bit or 6dB above the –98dB of CD. But in the CD format there is no scale factor and therefore the THD+N floor remains at a constant absolute level; a –20dB signal will see its THD+N 78dB down. In DCC, because of the floating-point amplitude description, THD+N will remain 92dB below the signal until the system noise floor is reached. Philips quotes a 108dB dynamic range for DCC (where CD, or R-DAT for that matter, can never go beyond 98dB). Using floating-point notation instead of linear coding means another gain in efficiency. By the way, all internal computation in PASC takes place in a 24-bit–wide processor.
One of the nicer properties of most sounds and music is that their content changes continuously. Which means that not all space in all 32 sub-bands would be fully in use; many might even be completely empty (above the threshold) from time to time. There is a certain coding space reserved for each of the 32 sub-bands. A temporarily not-so-busy sub-band thus wouldn't use all of its space, which would be a waste of efficiency. So PASC reallocates information from the busier sub-bands to empty or not-so-busy sub-bands (along with some address code for suitable re-reallocation at decoding to enable proper reconstruction).
If PASC does what it promises and literally discards only what could never be heard anyway, we're in for a revolution in both professional and consumer digital audio. It may be too early for specific speculations, but a host of possibilities passes the mind's eye. One of the limitations in digital audio has always been data storage; a higher basic sampling frequency or more amplitude bits would unavoidably consume a lot more space. PASC helps out here with a considerable reduction in data rate, a factor of four. One thing is clear in my opinion: if PASC works, there's no future for PCM in audio (footnote 9).—Peter van Willenswaard
Footnote 6: A good overview of the material is given by Vaidaynathan in IEEE Proceedings, January 1990, pp.56–93.—Peter van Willenswaard