Loss is nothing else but change, and change is Nature's delight.—Marcus Aurelius
Master Quality Authenticated (MQA), the audio codec from industry veterans Bob Stuart and Peter Craven, rests on two pillars: improved time-domain behavior, which is said to improve sound quality and what MQA Ltd. calls "audio origami," which yields reduced file size (for downloads) and data rate (for streaming). Last month I took a first peek at those time-domain issues, examining the impulse response of MQA's "upsampling renderer," the output side of this analog-to-analog system (footnote 1). This month I take a first look at the second pillar: MQA's approach to data-rate reduction. In particular, I'll consider critics' claims that MQA is a "lossy" codec.
Is MQA lossy? Yes, but that's not really the right question. That is my conclusion after reading widely about it, and talking and corresponding with experts, including MQA's Bob Stuart and digital engineers who don't support MQA. At worst, lossy is a cudgel—a scare word intended to evoke associations with MP3 and a negative emotional response. At best, framing the issue as one of lossy vs lossless largely misses the point.
Critics commonly claim that the Internet's ever-increasing download speeds render MQA's reduction in file sizes unnecessary. Why turn to an unproven "lossy codec" when, instead, we could use a familiar lossless codec like FLAC, or no compression at all? But as with every aspect of the codec, there's a serious philosophical perspective behind MQA's commitment to data-rate reduction. For Stuart, efficiency in the delivery of musical information is an aesthetic, even an ethical commitment.
The most important information in any audio recording, as everyone surely agrees, is what falls within the audioband of 20Hz–20kHz—ie, the range of frequencies audible to the human ear—and the audioband is adequately covered by CD's 44.1kHz sampling rate, with the caveat that squeezing a well-behaved antialiasing filter into the narrow transition band presents challenges (footnote 2). A sampling rate of 48kHz provides a bit more room for more gradual filtering.
So why not go for 48kHz? We could surely get consistently good sound from a 48kHz distribution format, assuming musicians and recording, mastering, and hardware engineers do their jobs well. However, it's widely thought that sound quality improves when the sampling rate is doubled, to 96kHz, and further improves when it's doubled again, to 192kHz, and on and on. That's the conventional wisdom, the result of many subjective experiences by countless audiophiles. But recently that rarest of things in high-end audio—actual scientific evidence—has emerged (footnote 3).
If nearly everyone agrees that increasing the sampling rate improves quality, most also agree that with each doubling the sonic benefit shrinks. And the necessary data rates quickly become formidable: With DXD, the highest-rate version of PCM in common use (352.8kHz), the data rate may exceed even the capacity of our own neural circuitry (footnote 4). Even if all those data were meaningful, they would be more than we could take in. Fortunately, they're not all meaningful—or equally meaningful. Most of those data, in fact, are noise.
MQA's goal, with their "audio origami," is to fix things so that the increase in sonic quality is proportionate to the increase in file size or rate of data streaming—the aesthetic and ethical commitment I mentioned. It became clear from interviews that Bob Stuart cares deeply about this. But as John Atkinson points out in this issue's "As We See It," the notion wasn't pioneered by Stuart and Craven. It was first expressed by Claude Shannon (1916–2001), who laid much of the foundation for digital audio. Indeed, there's a unit of measurement in communication theory that expresses how much information, on average, a single bit holds—a key idea for MQA compression. It's called the shannon.
Stuart's and Shannon's notions of efficiency are appealing and, it seems to me, common-sense. Few people drag bags of rocks on hiking trips, or walk the length of the city to visit the apartment next door. The prevailing view in audio, however, is that we should mindlessly hang on to every bit of musical data, no matter how few shannons it contains. Rejecting that approach is one of several radical things MQA does.
A fair number of recordings have music-correlated information above the audioband (footnote 5), especially just above it. You can't hear it, or not directly, but musical instruments do have harmonics up there. It's there, so we might as well keep it, or as much of it as possible. But if we don't try to distinguish between music and noise, this comes at a high penalty. Because the higher we go above the audioband, the less real information there is. Stuart mentioned in an e-mail to me that much fewer than 1% of recordings contain musical information above 48kHz—something he knows for a fact, because MQA's encoders collect such information as they do their work.
Audio origami comprises two distinct processes; MQA calls them folds. The first fold, which they call encapsulation, folds data from four times the baseband rate (176.4 or 192kHz sampling), or higher, down to half those rates. Very high-rate files—think DXD—may require two encapsulation folds.
The second fold, called type-L, folds data from 2x to 1x—from 96 to 48kHz, or from 88.2 to 44.1kHz. This is the range where most of the ultrasonic musical information is, so it's important to keep these data intact.
I spent a lot of time reading about this aspect of MQA, and several days grilling Stuart by e-mail. I managed to achieve a rough, schematic understanding, not of MQA per se but of what the issues are and aren't—not necessarily of how MQA works, but of how it could possibly work.
First, I'll focus on the encapsulation fold.
To answer this article's key question: MQA's encapsulation fold is lossy. That's okay, though—or so goes MQA's argument, and I mostly agree—because at those ultrasonic frequencies there's almost nothing but noise. Almost. And noise is just noise, which is to say, it's uniform. You just need to learn a few things about the character of the noise: its level, its spectrum, maybe something about phase relationships. You can preserve that information in minimal space—just a few coefficients of a power-series approximation, say. Once that's saved—buried beneath the noise floor, say—you could strip away the noise completely during encoding, and use the buried information to add back the noise during the decoding stage. Again, I'm not saying MQA works like this, but it could work this way, with little or no degradation in audio quality.
In that handful of recordings mentioned above, however, there is that tiny bit of musically relevant information present at such high frequencies. If it's there, we'd like to keep it. How does MQA deal with it? I believe it's largely preserved, though I admit I'm not 100% clear on this point. In our correspondence, Stuart emphasized the importance of preserving this "correlated spectral data," as he calls it—correlated, that is, to the actual music in the audioband, where it "manifests as micro-temporal structure"—and that's the whole point of MQA. The MQA encoder, he told me, can detect "spectral components above 48kHz," and has "several strategies" for dealing with it, including choosing from among more than 2000 encapsulation algorithms. The encoder will choose the option that will "allow the decoder to most accurately reproduce the signal 'envelope' and slew-rate." Does that mean that this musically relevant information is preserved—and how well? As I said, I'm not sure—Stuart never quite committed on this point—but it seems a lot of trouble to go to just to throw it out.
Now consider the L-type fold, which takes the data down to their transmission rate of 44.1 or 48kHz. I asked Stuart if the L-type fold is lossless in the usual, traditional sense—that the original data can be recovered in bit-perfect form. It's a complicated business, and his answer was characteristically nuanced, with several annotations. Here are the key points of Stuart's carefully annotated answer, in his own words:
"[T]he MQA encoder estimates the 'triangle' and a suitable guard band and can encode that in an L fold. In an L fold, the upper octave uses a specific 2-band predictor which gives a very good waveform estimate. That is then losslessly buried according to mastering choice. . . . The remaining 'touchup' signal is packed below the noise-floor."
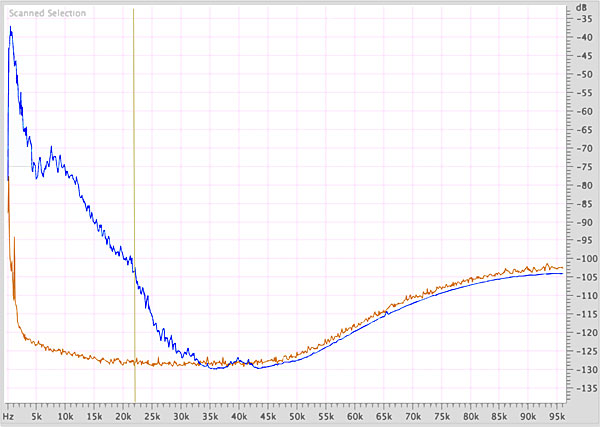
This is less complicated than it sounds. The left-pointing "'triangle'" is the region bounded by musical information above, the noise floor below and the lower end of the 2x frequency range on the left—in other words, it's where all this range's music-correlated data lives (fig.1). The "guard band" is a few bits below the noise floor that may contain recoverable musical information—because research has shown that we can hear into the noise floor to a depth of 10dB or so.
 "In any case," Stuart concludes, "a full stream is decoded to exactly the 'Core' resulting from the Encapsulation step."
Stuart is saying, then, that in an L-type fold, musical information above the noise floor, plus part of the noise, is losslessly compressed, then fully restored on decoding to exactly what it was before the L-type fold occurred. (The noise, apparently, is not perfectly rendered, or not all of it.) This all begins to hint at what the problem is with the whole lossless/lossy formulation: lossless compared to what?
To sum up the losslessness issue: In its folding and unfolding, MQA distinguishes between music-correlated data and noise, tries hard to retain the music-correlated data, but sensibly worries much less about preserving the noise bit by bit. This allows MQA to achieve their goal of preserving the benefits of high-resolution data without the burden of large, weighty swaths of pointless noise.
At this point I would love to show you what an MQA-decoded file looks like, point out all its nuances, and tell you what they mean. But I've recorded and analyzed—or tried to—dozens of MQA files, and have noticed few patterns. I've likely encountered most of MQA's 2000+ encapsulation algorithms: Every MQA file seems to do things in a different way, diverging from the apparent non-MQA source in many different ways, and sometimes not at all. Every time I thought was getting a handle on some aspect of MQA, I'd look at another file and find that it didn't conform to my theory.
So instead of showing you a typical MQA file—there's no such thing—I'll show you an outlier. I captured the output of a Mytek HiFi Brooklyn DAC+ with its built-in MQA decoding enabled, with my Focusrite Scarlett 2i2 audio interface. The fast Fourier transform (FFT) was carried out in Adobe Audition. The Focusrite is limited to a top sampling rate of 192kHz, so I've missed some high frequencies. The Focusrite contributes its own noise at frequencies above 60kHz or so, but its contribution should be the same for all data; the differences you see are surely real.
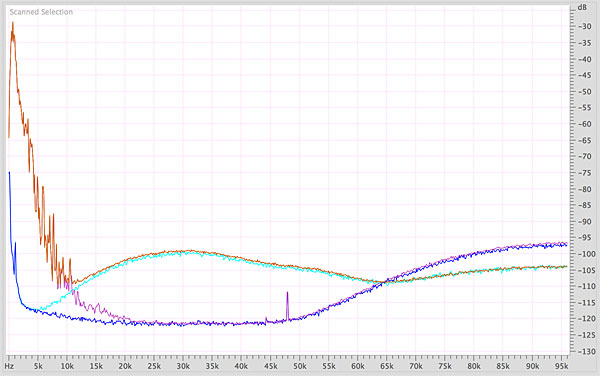
Fig.2 shows the frequency spectrum of the run-in noise and several seconds of music for an MQA file and the original DXD file it was very likely encoded from. DXD noise is blue, MQA noise is turquoise; DXD data are magenta, MQA data are orange.
"In any case," Stuart concludes, "a full stream is decoded to exactly the 'Core' resulting from the Encapsulation step."
Stuart is saying, then, that in an L-type fold, musical information above the noise floor, plus part of the noise, is losslessly compressed, then fully restored on decoding to exactly what it was before the L-type fold occurred. (The noise, apparently, is not perfectly rendered, or not all of it.) This all begins to hint at what the problem is with the whole lossless/lossy formulation: lossless compared to what?
To sum up the losslessness issue: In its folding and unfolding, MQA distinguishes between music-correlated data and noise, tries hard to retain the music-correlated data, but sensibly worries much less about preserving the noise bit by bit. This allows MQA to achieve their goal of preserving the benefits of high-resolution data without the burden of large, weighty swaths of pointless noise.
At this point I would love to show you what an MQA-decoded file looks like, point out all its nuances, and tell you what they mean. But I've recorded and analyzed—or tried to—dozens of MQA files, and have noticed few patterns. I've likely encountered most of MQA's 2000+ encapsulation algorithms: Every MQA file seems to do things in a different way, diverging from the apparent non-MQA source in many different ways, and sometimes not at all. Every time I thought was getting a handle on some aspect of MQA, I'd look at another file and find that it didn't conform to my theory.
So instead of showing you a typical MQA file—there's no such thing—I'll show you an outlier. I captured the output of a Mytek HiFi Brooklyn DAC+ with its built-in MQA decoding enabled, with my Focusrite Scarlett 2i2 audio interface. The fast Fourier transform (FFT) was carried out in Adobe Audition. The Focusrite is limited to a top sampling rate of 192kHz, so I've missed some high frequencies. The Focusrite contributes its own noise at frequencies above 60kHz or so, but its contribution should be the same for all data; the differences you see are surely real.
Fig.2 shows the frequency spectrum of the run-in noise and several seconds of music for an MQA file and the original DXD file it was very likely encoded from. DXD noise is blue, MQA noise is turquoise; DXD data are magenta, MQA data are orange.
 The music is Prolog, the first section of Olav Anton Thommessen's Veslemøy Synsk (after Grieg), for soprano and piano (Marianne Beate Kielland and Nils Anders Mortensen), recorded to DXD and available in several formats (2L 2L-078). In MQA or DXD, the music is great and the sound is superb.
Not only did I fail to hear a difference, I heard nothing at all before the first piano note, in MQA or DXD. That run-in noise was inaudible. Recording engineer Morten Lindberg was careful in his choices—no surprise.
Earlier, I wrote that the lossiness/losslessness question is beside the point. Here's what I was getting at. There certainly are differences in the MQA version of this recording, and the changes due to the MQA encoding/decoding seem to indicate some loss of resolution, even if it isn't audible. And yet, whatever the cause of the differences between the DXD and MQA versions—whether the results of origami or of some other change wrought during encoding—well, we already knew that. We already knew that MQA changes the music. MQA's goal is to make music sound better, and you can't make music sound better without changing how it sounds. Lossiness is beside the point.
How, then, should we evaluate MQA? The next step would be to confirm that it indeed offers superior time-domain behavior, which will require cooperation from Bob Stuart and the MQA team. The next step after that would be to get a fix on MQA's sound in some rigorous way—something beyond casual subjective observations. Then we can start to weigh, with analysis and careful listening, any frequency-domain degradation against time-domain improvement.
Finally, we need to decide whether MQA is good or bad for music. We audiophiles probably won't get to decide MQA's fate, but we do get to have an opinion.—Jim Austin
The music is Prolog, the first section of Olav Anton Thommessen's Veslemøy Synsk (after Grieg), for soprano and piano (Marianne Beate Kielland and Nils Anders Mortensen), recorded to DXD and available in several formats (2L 2L-078). In MQA or DXD, the music is great and the sound is superb.
Not only did I fail to hear a difference, I heard nothing at all before the first piano note, in MQA or DXD. That run-in noise was inaudible. Recording engineer Morten Lindberg was careful in his choices—no surprise.
Earlier, I wrote that the lossiness/losslessness question is beside the point. Here's what I was getting at. There certainly are differences in the MQA version of this recording, and the changes due to the MQA encoding/decoding seem to indicate some loss of resolution, even if it isn't audible. And yet, whatever the cause of the differences between the DXD and MQA versions—whether the results of origami or of some other change wrought during encoding—well, we already knew that. We already knew that MQA changes the music. MQA's goal is to make music sound better, and you can't make music sound better without changing how it sounds. Lossiness is beside the point.
How, then, should we evaluate MQA? The next step would be to confirm that it indeed offers superior time-domain behavior, which will require cooperation from Bob Stuart and the MQA team. The next step after that would be to get a fix on MQA's sound in some rigorous way—something beyond casual subjective observations. Then we can start to weigh, with analysis and careful listening, any frequency-domain degradation against time-domain improvement.
Finally, we need to decide whether MQA is good or bad for music. We audiophiles probably won't get to decide MQA's fate, but we do get to have an opinion.—Jim Austin
Footnote 1: I'll be writing more about MQA's time-domain claims in future articles. Footnote 2: Kinks and corners in a filter induce ringing in the time domain. Footnote 3: As with many things in high-end audio, the evidence is mainly anecdotal, though several studies have been done, and the results of those studies have been combined into a meta-analysis by Joshua D. Reiss, published in 2016. The conclusion: Higher sampling rates are audible, but the effect is small.
Footnote 4: Writing about this topic requires some awkward nomenclature: If a trumpet makes noise but you can't hear it, is it music? If a tree falls in the woods . . .
Footnote 5: Although the instruments with the most ultrasonic information tend to be those, like cymbals, that don't really have harmonics, in the usual sense.
Fig.1 Spectral analysis, 0Hz–96kHz, the "musical triangle" (blue trace), bounded by noise (orange trace) at its base and the baseband Nyquist frequency (vertical line at 22.05kHz) to its left (5dB/vertical div.).
Fig.2 Spectral analysis, 0Hz–96kHz, Prolog for soprano and piano, DXD run-in noise (blue), MQA run-in noise (turquoise), DXD music data (magenta), MQA music data (orange) (5dB/vertical div.).
This measurement shows the most dramatic departure I've seen of an MQA file from the file it was made from. The noise added by MQA begins to rise at about 10kHz—well down into the audioband—and reaches +10dB or a little more by 20kHz. The noise continues to rise above the audioband, to more than 20dB by 30kHz.
The difference between these files was so large that I thought I might be able to hear it, especially in the recording's unusually long run-in section of about four seconds. So I did what I could to minimize extraneous environmental noise, waited (and waited) for my building's boiler fan to turn off, and turned the volume up loud. I played the run-in and the first few seconds of music over and over. My RadioShack SPL meter indicated peak levels in excess of 110dB (C-rated, slow).
Footnote 1: I'll be writing more about MQA's time-domain claims in future articles. Footnote 2: Kinks and corners in a filter induce ringing in the time domain. Footnote 3: As with many things in high-end audio, the evidence is mainly anecdotal, though several studies have been done, and the results of those studies have been combined into a meta-analysis by Joshua D. Reiss, published in 2016. The conclusion: Higher sampling rates are audible, but the effect is small.