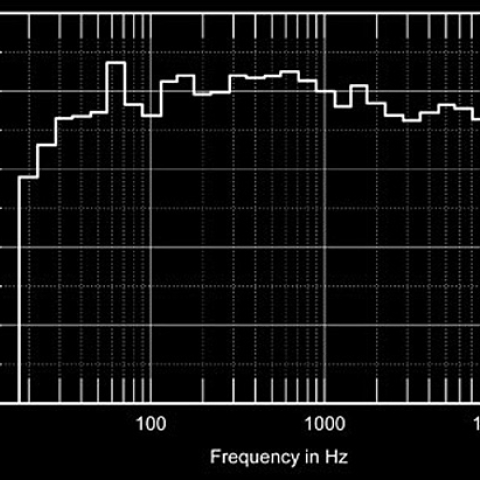
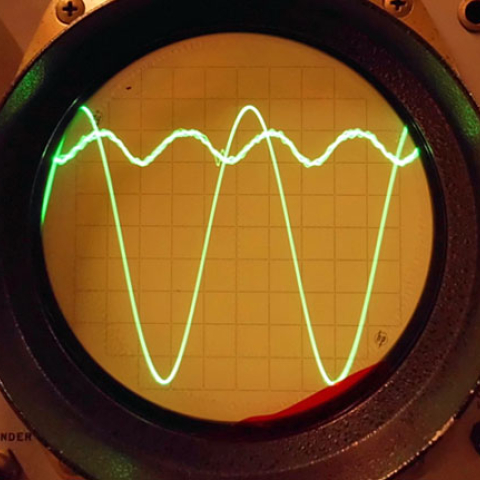
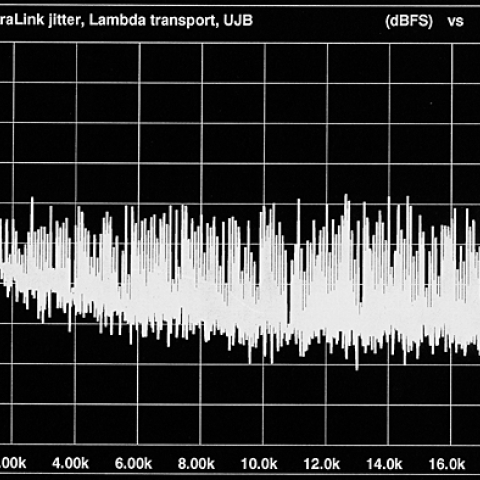
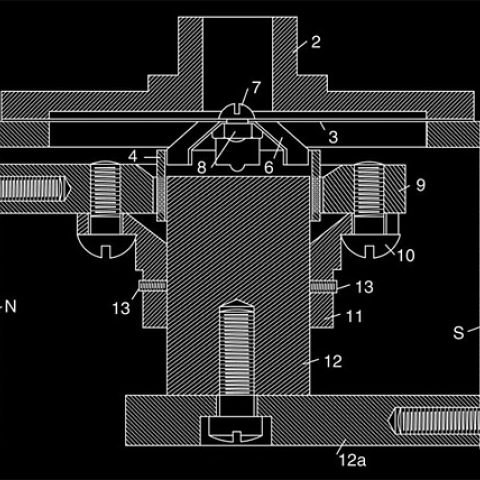
Given that the results came out as they did, can we conclude that the differences between the amplifiers are not audible? That is, of course, one possible conclusion, but a null result such as this raises many questions and alternative hypotheses and is essentially uninterpretable. While a positive result points to one or to a small set of conclusions, a null result tells us very little. Anything that can mess up a study can cause a null result. It is much easier to run a flawed study than a valid one and hence very easy to get a null result. (For this reason is it virtually impossible to publish a scientific paper that reports a null finding.) In this case some factors that could have led to a null finding can be suggested. An obvious one is the listening conditions. With over 50 listeners packed into the testing room, we would assume that only a few were in a position nicely located between the speakers without a human body in the way. Another factor, characteristic of all the comparative listening tests we know of, is the relatively brief 90-second exposure each observer had. As Atkinson pointed out in the introduction to the Stereophile study, it may take listening sessions much longer than 90 seconds for differences between amplifiers to be apparent. Still another problem could result from people being influenced, consciously or not, by the gestures, body language, and possibly even by visible response-sheet answers of others in the room. If people are more concerned with their neighbors' subtle cues than the sounds they are supposed to be listening to, accuracy could very well fall to chance. Finally, we believe that design problems similar to those found in this study could either obscure real differences or create artificial ones.
One problem we have found in most of the amplifier tests we have read has to do with the particular selections of music used for "same" and "different" trials. In virtually every case a given selection is presented to listeners in either a "same" trial or a "different" trial, but not in both. This procedure creates a problem because a given piece may incline the listener to judge "same" or "different," whatever the truth may be—possibly because the selection's auditory characteristics are difficult to remember or because of any of dozens of extraneous factors known to affect perceptual judgments of this type. It is clear that a problem is created if a selection that biases a listener to say "same" is played through two different amplifiers; the bias will cause most people to give the wrong answer, and overall accuracy will seem worse than it really is. If, on the other hand, this selection is played twice through the same amplifier, the bias will cause listeners to give an answer that falsely inflates their accuracy. Biases of this sort should average out over a large set of selections, but studies of amplifier audibility tend to use such a small number of selections that a strong bias for one or two selections can greatly affect the results. An alternative to using a large set of selections is a design in which each selection is presented, to different listeners, in both a "same" and a "different" trial. The study we report here used such a design, which we will describe below. A repeat test
In order to overcome some of the flaws in the Stereophile study, we decided to set up a more nearly ideal testing situation. We purchased an Adcom GFA-555 power amp and a pair of VTL Monoblock 300s (both used, both checked out as up to current specs). Testing took place in a classroom at Pomona College that had been outfitted for listening and recording for a different project. This room had nonresonant masonry walls, ceiling, and floor, as well as a nonresonant (but not very effective) dropped acoustical ceiling. It was carpeted, and bats of jute rug pad were used to reduce reflections and to cover the windows and stifle their resonances. The signal source was a VTL-modified Magnavox CD player that fed the two amplifiers in parallel through an attenuating network with film resistors and Bourns potentiometers, the pots being used to equalize the effective gain for both amps. Before every listening session we equalized the outputs of the amplifiers at 1kHz, using a Fluke digital true-RMS meter accurate to three significant figures, and with the amplifiers driving the speakers.
Mogami Neglex was used for all interconnects, and all connections were soldered. The outputs of the amplifiers were fed through very robust 250-amp switches. The VTLs' outputs were switched to a 16 ohm load when it was not driving the speaker; the Adcom was not loaded when it was not driving the speaker. Cardas cable was used for all speaker cable. Several short pieces of cable were needed for the switching box, and two 18' lengths of Cardas Hexlink fed the speakers, Martin-Logan CLSes. We chose the CLSes because they are uncolored and transparent speakers that seemed likely to reveal differences between the amplifiers—also because we had no access to a B&W 801 of the kind used in the Stereophile test. The listening panel consisted of eight people. Of these, three had long-term interests in high-fidelity sound and had "high-end" systems at home. The rest were recruited from those working in the building during the Summer. These five had interests in audio and music but were not consumers of high-end equipment. People were given the test either singly or in groups of two. They were well-positioned with respect to the speakers and, when two were tested at the same time, they sat so as not to be able to observe each other's reactions or responses (the room was very dimly lit).
In order to overcome some of the flaws in the Stereophile study, we decided to set up a more nearly ideal testing situation. We purchased an Adcom GFA-555 power amp and a pair of VTL Monoblock 300s (both used, both checked out as up to current specs). Testing took place in a classroom at Pomona College that had been outfitted for listening and recording for a different project. This room had nonresonant masonry walls, ceiling, and floor, as well as a nonresonant (but not very effective) dropped acoustical ceiling. It was carpeted, and bats of jute rug pad were used to reduce reflections and to cover the windows and stifle their resonances. The signal source was a VTL-modified Magnavox CD player that fed the two amplifiers in parallel through an attenuating network with film resistors and Bourns potentiometers, the pots being used to equalize the effective gain for both amps. Before every listening session we equalized the outputs of the amplifiers at 1kHz, using a Fluke digital true-RMS meter accurate to three significant figures, and with the amplifiers driving the speakers.