The final technical presentation was by Karlheinz Brandenburg, the man behind ASPEC, a competing low–bit-rate encoder. His presentation discussed an unusual phenomenon of these systems: the limited time resolution of a frequency-domain encoder results in "pre-echoes" in which quantization error (distortion) appears before the signal. This is a significant issue because large amounts of quantization error are generated by encoding with so few bits. The correctly coded signal reportedly masks this large quantization error. The ASPEC system reportedly minimizes this effect (footnote 2).
Dr. Brandenburg noted that there was a significant difference in sound quality between ASPEC's 64kb/s and 96kb/s data rates, but not much difference between 96kb/s and 128kb/s (64kb/s is about 1/11th the data rate for 16-bit linear PCM digital audio as found on a CD). ASPEC has scored well in subjective testing compared to other coders, but is more complex and introduces a greater delay time in decoding the signal.
The final presentation was by Christer Grewin, who headed the official subjective testing of these systems at the Swedish National Radio Company. He reported on the methodology, results, and conclusions of these tests. Swedish Radio's mandate was to determine which codec (bit-rate reduction encoder/decoder system) was the best sonically, and also to decide if the best system's audio performance was adequate for use in Digital Audio Broadcasting. Clearly, this was not a trivial undertaking. I was thus very curious about how the tests were devised, and the various systems' subjective performances.
I was heartened by the paper's introduction: "Subjective assessments or listening tests have always played an important part in the evaluation of audio equipment. Maybe even more so today. A major part of today's (at least professional) audio equipment, show electric data with no or very little degradation compared to a straight wire. Still, audible differences can be detected.
"For certain types of digital audio equipment there are no adequate methods of objective measurements available."
With that auspicious beginning, Mr. Grewin described the test methodology. First, 60 "expert" listeners were chosen; 23 were appointed by Swedish Radio, 24 came from four codec development groups, and the rest were selected from the AES and EBU (European Broadcast Union). Half the listeners were from outside Sweden. The CCIR listening test recommendations (CCIR 562-2) states that any system intended for high-quality broadcasting or reproduction shall be assessed by "expert" listeners exclusively. It was not specified what criteria were used to determine who was an "expert listener" for these tests.
Ten musical selections were chosen to evaluate the codecs, based on previous auditioning through the various codecs. They were: 1) Suzanne Vega (unaccompanied voice), 2) Tracy Chapman, 3) glockenspiel, 4) fireworks, 5) Ornette Coleman's Dreams, 6) a bass synthesizer, 7) castanets, 8) male speech, 9) bass guitar, and 10) trumpet. The playback system wasn't specified, but the D/A converter was a Philips DAC 960.
The four codecs evaluated were MUSICAM, ASPEC, ATAC (called ATRAC in Sony's recordable Mini-Disc), and SB/ACPCM, a less well-known system. Each was evaluated at three bit-rates: 128kb/s, 96kb/s, and 64kb/s. The latter two systems weren't fully implemented when the tests were conducted; consequently, no data were provided on these two systems. Because each codec introduces a different amount of decoding delay which could identify the particular codec, a system was devised in which the signals from the reference source and each codec were put through a digital delay line, making the delays equal.
The listening tests were "Triple Stimulus, Hidden Reference, Double Blind." Each listener sat with a box that had a level control and buttons for selecting the presentations and grading the codec in relation to the source. The subject was allowed to switch between three presentations: A, B, and C. Presentation A was always the reference signal from a DAT machine with no codec (16-bit linear PCM), and thus known to the subject. B was either the same signal encoded and decoded by the codec under evaluation (in real time), or the unaltered reference signal. C was either the reference or the codec, but the opposite of presentation B. The determination of whether B or C was the codec was chosen randomly.
The listener was to first identify if B or C was the codec, then rate the introduced degradation. The "CCIR Impairment Scale" was used, offering five choices of degradation. A "1" rating was classified as "very annoying," "2" was "annoying," "3" was "slightly annoying," "4" was "perceptible but not annoying," and a score of "5" was "imperceptible." Throughout the test, more than 20,000 grades were obtained, half of them on the hidden reference and half on the codecs.
The analysis of the codecs' performance was broken down according to musical selection. This yielded some interesting information: Some music was much more revealing of the codecs' degradation than other music. The most critical appeared to be Suzanne Vega's unaccompanied voice, the least critical the bass synthesizer and fireworks.
Fig.1 is a graphical representation of the data from one test, comparing MUSICAM at 128kbs to the reference. The numbers 1–10 across the bottom correspond to the ten musical selections listed above. The left-hand bar over each number is the codec's rated performance on that particular musical selection, the right-hand is the reference. The greater the difference between the bars' height, the worse the codec's sound quality. If the black and crosshatched boxes on top of the bars don't overlap, then there is "statistically significant" evidence of audible impairment. The paper presented 14 graphs representing the test data.
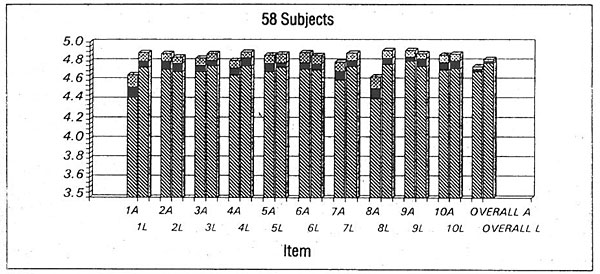
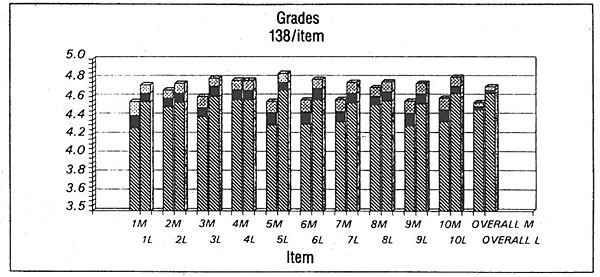 Swedish Radio's belief that the encoding algorithms could be improved were borne out in the second set of tests. The individual codecs performed much better in the 1991 tests, and there was very high correlation between the 1990 and 1991 results, validating the test methodology in SR's view. It was determined that "Both codecs have now reached a level of performance where they fulfill the EBU requirements for a distribution codec." Fig.2 shows the performance of the so-called "Layer III" codec (a combination of ASPEC and MUSICAM [subsequently to become ubiqutous as MP3—Ed.] ) at 128kb/s, the target data rate for DAB. (The musical selections were slightly different in the 1991 tests and don't correlate to the ten listings above, with the exception of #1, Suzanne Vega, footnote 3).
Swedish Radio's belief that the encoding algorithms could be improved were borne out in the second set of tests. The individual codecs performed much better in the 1991 tests, and there was very high correlation between the 1990 and 1991 results, validating the test methodology in SR's view. It was determined that "Both codecs have now reached a level of performance where they fulfill the EBU requirements for a distribution codec." Fig.2 shows the performance of the so-called "Layer III" codec (a combination of ASPEC and MUSICAM [subsequently to become ubiqutous as MP3—Ed.] ) at 128kb/s, the target data rate for DAB. (The musical selections were slightly different in the 1991 tests and don't correlate to the ten listings above, with the exception of #1, Suzanne Vega, footnote 3).
 Gerzon prefaced these remarks by saying that older technology tends to preserve spatial information and newer technology doesn't, apparently a reference to the controversy over analog and digital. This was an excellent point, and one that I'm surprised Swedish Radio didn't consider, especially since the methodology and statistical analysis were so rigorous. This omission is even more glaring when one realizes that the low-level information thrown away by the codec is the information likely to contain spatial cues.
Other discussions focused on the effects of cascading codecs in several encode/decode cycles. This is an important issue; it is likely that broadcast signals will be transmitted and stored for later broadcast. Everyone on the panel agreed that multiple encode/decode cycles were a problem, producing "cumulative impairment." Two cascades were reportedly audible, with very rapid degradation associated with each successive generation.
One question not raised during the panel discussion was the effect of the playback system and environment on unmasking. All these systems produce huge objective errors that are presumably masked by the correctly coded wanted signal, much the way the music masks tape hiss in an analog tape recorder. If the playback system produces large amplitude errors—very common in car stereos—the horrible distortion hiding beneath the signal may be unmasked. These amplitude errors are often intentionally introduced by graphic equalizers.
When asked about professional uses of this technology, the MUSICAM designer said that professional and consumer systems should be very similar if not identical for ease of transfer: "There should be a very simple relationship between professional and consumer versions." He also asserted that these systems are currently "suitable for production and archiving." Karlheinz Brandenburg urged caution, saying that "more work was needed" before such systems are ready for making master recordings.
Christer Brewin, who conducted the subjective assessments, suggested that the drive to implement these very new systems was overly hasty: "...standardization has been rushed on us...and mistakes will occur."
Bob Stuart made an interesting point: Masking thresholds imply a known playback level. How well do these systems work over the very wide range of playback volumes encountered in the real world? This question went unanswered.
Bob's next question, however, produced a disturbing revelation. He asked "What happens when you run out of bits?" to encode the signal. He also asked if there was any thought to putting a flag in the data to indicate that the encoder had violated the masking model.
Karlheinz Brandenburg's reply was bluntly honest: "We run out of bits all the time. Nearly all the time we wish to have more bits." Yves-François Dehery added that "you do not follow the psychoacoustic rules" (the masking model) when you run out of bits.
The panel discussion ran well over the allotted time, an indication of the interest in low–bit-rate encoding and the realization that such techniques are inevitable in all areas of audio.
I'll conclude this report on the conference and the state of bit-rate reduction with a question from a member of the audience. His query is the very embodiment of the kind of thinking that led to the development of these frightening schemes in the first place. The gentleman asked if, because few bits are used in quiet passages, "it was possible to commercially exploit those unused data areas," particularly during "the silence between notes."—Robert Harley
Gerzon prefaced these remarks by saying that older technology tends to preserve spatial information and newer technology doesn't, apparently a reference to the controversy over analog and digital. This was an excellent point, and one that I'm surprised Swedish Radio didn't consider, especially since the methodology and statistical analysis were so rigorous. This omission is even more glaring when one realizes that the low-level information thrown away by the codec is the information likely to contain spatial cues.
Other discussions focused on the effects of cascading codecs in several encode/decode cycles. This is an important issue; it is likely that broadcast signals will be transmitted and stored for later broadcast. Everyone on the panel agreed that multiple encode/decode cycles were a problem, producing "cumulative impairment." Two cascades were reportedly audible, with very rapid degradation associated with each successive generation.
One question not raised during the panel discussion was the effect of the playback system and environment on unmasking. All these systems produce huge objective errors that are presumably masked by the correctly coded wanted signal, much the way the music masks tape hiss in an analog tape recorder. If the playback system produces large amplitude errors—very common in car stereos—the horrible distortion hiding beneath the signal may be unmasked. These amplitude errors are often intentionally introduced by graphic equalizers.
When asked about professional uses of this technology, the MUSICAM designer said that professional and consumer systems should be very similar if not identical for ease of transfer: "There should be a very simple relationship between professional and consumer versions." He also asserted that these systems are currently "suitable for production and archiving." Karlheinz Brandenburg urged caution, saying that "more work was needed" before such systems are ready for making master recordings.
Christer Brewin, who conducted the subjective assessments, suggested that the drive to implement these very new systems was overly hasty: "...standardization has been rushed on us...and mistakes will occur."
Bob Stuart made an interesting point: Masking thresholds imply a known playback level. How well do these systems work over the very wide range of playback volumes encountered in the real world? This question went unanswered.
Bob's next question, however, produced a disturbing revelation. He asked "What happens when you run out of bits?" to encode the signal. He also asked if there was any thought to putting a flag in the data to indicate that the encoder had violated the masking model.
Karlheinz Brandenburg's reply was bluntly honest: "We run out of bits all the time. Nearly all the time we wish to have more bits." Yves-François Dehery added that "you do not follow the psychoacoustic rules" (the masking model) when you run out of bits.
The panel discussion ran well over the allotted time, an indication of the interest in low–bit-rate encoding and the realization that such techniques are inevitable in all areas of audio.
I'll conclude this report on the conference and the state of bit-rate reduction with a question from a member of the audience. His query is the very embodiment of the kind of thinking that led to the development of these frightening schemes in the first place. The gentleman asked if, because few bits are used in quiet passages, "it was possible to commercially exploit those unused data areas," particularly during "the silence between notes."—Robert Harley
Footnote 2: Quantization distortion is what gives digital audio that gritty, granular coarseness on low-level signals. When the tail end of reverb decay sounds like sandpaper brushing against the microphone, quantization error is to blame.—Robert Harley Footnote 3: The proceedings of the conference, Images of Audio, which include the description of these subjective tests as well as Malcolm Hawksford's digital primer, are available from the Audio Engineering Society Inc., 60 E. 42nd St., New York, NY 10165-0075. Web: www.aes.org. The paper on subjective assessment of low–bit-rate encoders is far more detailed than described here.—Robert Harley
Footnote 4: Michael Gerzon is a theoretical mathematician as well as an audio designer. He has used his considerable analytical skills to argue the audiophile position on many occasions. At the 1991 Paris AES convention, he presented a paper that called into question the psychoacoustic masking models on which all these codecs are based. His contention is that when the error is correlated with the signal, the masking threshold is reduced by as much as 30dB. If he is correct, the present bit-rate reduction systems are fatally flawed. He also presented six papers at the New York AES convention in October 1991, one of which was entitled "Limitations of Double-Blind AB Testing."—Robert Harley
Fig.1 Listening Test Scores, 128kbps MUSICAM (LH bars vs linear reference, after "Subjective Assessments of Low Bit-rate Audio Codecs, by Christopher Grewin and Thomas Ryden, Images of Audio, the collected papers of the 1991 AES conference, p.94.
These tests were performed twice, once in 1990 and again in 1991. After the first round of subjective testing in 1990, Swedish Radio "...came to the conclusion that none of the codecs could be generally accepted for use as distribution codecs by the broadcasters, at the stage of development by the time of the tests in July, 1990." They noted that ASPEC had the best sound quality, but had the greatest complexity and longest delay time (an important factor in broadcast applications). MUSICAM sounded slightly worse, but used simpler encoding and decoding hardware. This prompted SR to suggest that the ASPEC and MUSICAM development groups combine forces and produce a system with the best parts of each codec.
Although they regarded the level of impairment "small," Swedish Radio based their rejection on the belief that there was great potential for improving the codecs' performance. In addition, the realization that the selected system may well be the replacement for AM and FM broadcasting for the next 30 years or more weighed heavily in the decision. The paper used a metaphor to justify this cautious approach: "Artifacts that may be difficult to detect at a first listening will be more and more obvious as time goes by. It can be compared with somebody who moves into a new house. The first time he looks through the window he only sees the beautiful view. After a few days he detects a small flaw in the glass and from that moment he cannot look through the window without seeing the flaw."
Fig.2 Listening Test Scores, 128kbps Layer III (LH bars vs linear reference, after "Subjective Assessments of Low Bit-rate Audio Codecs, by Christopher Grewin and Thomas Ryden, Images of Audio, the collected papers of the 1991 AES conference, p.101.
The panel discussion later that evening provided some, but not nearly enough, challenge to these bit-rate reduction systems. Michael Gerzon (footnote 4). noted that none of the musical selections used in evaluating the codecs was of naturally miked classical music; instead, all the program material was made with techniques that don't preserve spatial cues. Because this was the case, he argued, the listening tests would not reveal the codecs' possibly destructive effects on spatial information.
Footnote 2: Quantization distortion is what gives digital audio that gritty, granular coarseness on low-level signals. When the tail end of reverb decay sounds like sandpaper brushing against the microphone, quantization error is to blame.—Robert Harley Footnote 3: The proceedings of the conference, Images of Audio, which include the description of these subjective tests as well as Malcolm Hawksford's digital primer, are available from the Audio Engineering Society Inc., 60 E. 42nd St., New York, NY 10165-0075. Web: www.aes.org. The paper on subjective assessment of low–bit-rate encoders is far more detailed than described here.—Robert Harley















