In cases where microphones are placed close to instruments and exposed to high SPLs, the problem of mike self-noise is significantly reduced. But in situations where mikes are placed well back from the performers, a reduction of mike self-noise might elicit sound-quality dividends. This isn't a subject I've looked into in any depth, but an array of microphone capsules might, with suitable post-processing of their signals, provide a workable solution, in the same way that paralleled transistors can be used in the input stage of a moving-coil preamp to reduce its noise level. Ten paralleled devices lower the noise floor by 10dB; a hundred are needed to reduce it by 20dB.
The Sound of Dither
We've seen that most of the 24-bit recordings I've analyzed can be truncated to 16-bit sans dither without this introducing many—sometimes any—signal-correlated quantization errors that are detectable either by listening to the quantization error or by applying the lag 1 autocorrelation test. Choosing not to dither such recordings when converting them to 16-bit can be justified on pure engineering grounds because it can never be good practice to unnecessarily compromise signal/noise ratio. But I suspect most audio professionals would rather play safe and add dither, in the knowledge that the degradation in noise performance is quite small and in the expectation that it will pass unnoticed. But what if the addition of unnecessary dither actually compromises sound quality? This is not so left-field a notion as it may seem. There is no question that noise at this level is audible, or that it can influence sound quality. To appreciate this, you have only to note the development of noise-shaped dither and the strongly held preferences for different noise-shaping algorithms among recording and mastering engineers. Some even eschew all noise-shaped dithers, preferring instead the flat-spectrum alternative. Still, it is a surprise to find that such small changes in noise floor are audible even when flat-spectrum TPDF dither is added to signals that already have a noise floor of higher amplitude.
I don't claim to understand why this should be the case, but my ears tell me it is. I have compared dithered and undithered 16-bit versions of all of the tracks listed in Table 1, and in every case except track 4, using the 24-bit original as the reference, I prefer the undithered version. Certainly the dithered and undithered versions sound different, despite the apparently innocuous nature of the quantization error in the undithered case. When, recently, I tried this out on an audio-industry guest, he expressed the same preference. I also exposed him to another experiment that may offer at least a partial explanation.
What I did for this was to generate five different noise signals—all with the same RMS amplitude but different PDFs—and add them to a piano recording ripped from the European Broadcasting Union's Sound Quality Assessment Material (SQAM) CD. In this track the inherent noise level is about –85dBFS, so the noise was added at an amplitude about 20dB greater in order to swamp it.
Varying the PDF of the added noise was achieved by summing together different numbers of random-number generators, from 2 to 5 (all this was done in software, and the processed files burned to CD-R for the listening comparison). As fig.6 shows, adding the output of two random-number generators results in noise with a triangular PDF; increasing the number of random-number generators further makes the noise more Gaussian in nature; ie, it has a PDF shaped more like the bell curve of the normal distribution. Gaussian noise is what we experience of analog processes, and might therefore be more natural to the ear than TPDF noise, whose PDF is like nothing we normally encounter in nature.
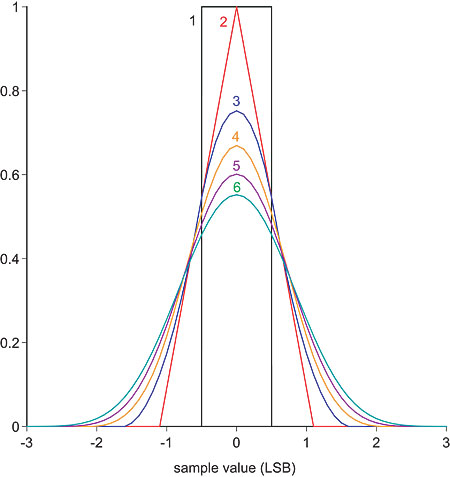 Fig.6 How summing the outputs of different numbers of independent random-number generators can be used to create noise with different probability density functions. A single random-number generator produces rectangular probability density function (RPDF) noise (black trace). Combining two random-number generators produces triangular probability density function (TPDF) noise (red). As the number of random-number generators increases, the PDF noise becomes more like that of Gaussian analog noise.
The first thing you notice when comparing the piano tracks with the different noise signatures—again with the original as a reference—is that TPDF noise is more irritating than the more Gaussian-like alternatives. And it has an effect on the sound of the piano, which is more "clangy" than in the original, or in those tracks with a more natural noise PDF. Of course, this experiment was conducted with an amplitude of noise getting on toward 30dB higher than 16-bit TPDF dither, but it may be that even at this much lower amplitude, and even when the dither is added to more naturally distributed noise, the ear can still detect it as something unnatural.
Thinking along these lines, I have also experimented with how best to "hide" TPDF dither within a typical audio signal. It is normal practice in two-channel or multichannel recordings to use uncorrelated dither in each channel. This has the advantage that summing two uncorrelated noise signals increases the noise amplitude by 3dB, whereas summing two correlated noise signals increases the amplitude by 6dB. So uncorrelated dither promises a superior S/N ratio in normal listening, and if the channels are summed to mono or a multichannel signal is downmixed to stereo.
But there are other ways to look at this. Uncorrelated dither becomes part of the S (difference) component of a stereo signal, which is usually of much lower amplitude than the M (sum) component because the audio signals in each channel are typically quite highly correlated. This raises the possibility that dither noise might be easier to hide if it is identical in both channels rather than uncorrelated. It is also feasible that having the dither noise precisely located in the soundstage makes it easier to "tune out," whereas the diffuse nature of uncorrelated dither is less easy to ignore.
I have tested this idea only briefly, using the same piano track and the same high noise level. The experiment would need to be repeated at more representative noise amplitudes and with a range of source material to reach any firm conclusions, but what I've heard encourages me to believe this is an idea worth pursuing. Tony Faulkner put me on to this and suggested that this issue was probably the subject of research by Sony and others in the early years of digital audio, although I can't recall ever seeing a reference to it.
Thoughts
Fig.6 How summing the outputs of different numbers of independent random-number generators can be used to create noise with different probability density functions. A single random-number generator produces rectangular probability density function (RPDF) noise (black trace). Combining two random-number generators produces triangular probability density function (TPDF) noise (red). As the number of random-number generators increases, the PDF noise becomes more like that of Gaussian analog noise.
The first thing you notice when comparing the piano tracks with the different noise signatures—again with the original as a reference—is that TPDF noise is more irritating than the more Gaussian-like alternatives. And it has an effect on the sound of the piano, which is more "clangy" than in the original, or in those tracks with a more natural noise PDF. Of course, this experiment was conducted with an amplitude of noise getting on toward 30dB higher than 16-bit TPDF dither, but it may be that even at this much lower amplitude, and even when the dither is added to more naturally distributed noise, the ear can still detect it as something unnatural.
Thinking along these lines, I have also experimented with how best to "hide" TPDF dither within a typical audio signal. It is normal practice in two-channel or multichannel recordings to use uncorrelated dither in each channel. This has the advantage that summing two uncorrelated noise signals increases the noise amplitude by 3dB, whereas summing two correlated noise signals increases the amplitude by 6dB. So uncorrelated dither promises a superior S/N ratio in normal listening, and if the channels are summed to mono or a multichannel signal is downmixed to stereo.
But there are other ways to look at this. Uncorrelated dither becomes part of the S (difference) component of a stereo signal, which is usually of much lower amplitude than the M (sum) component because the audio signals in each channel are typically quite highly correlated. This raises the possibility that dither noise might be easier to hide if it is identical in both channels rather than uncorrelated. It is also feasible that having the dither noise precisely located in the soundstage makes it easier to "tune out," whereas the diffuse nature of uncorrelated dither is less easy to ignore.
I have tested this idea only briefly, using the same piano track and the same high noise level. The experiment would need to be repeated at more representative noise amplitudes and with a range of source material to reach any firm conclusions, but what I've heard encourages me to believe this is an idea worth pursuing. Tony Faulkner put me on to this and suggested that this issue was probably the subject of research by Sony and others in the early years of digital audio, although I can't recall ever seeing a reference to it.
Thoughts
I've covered quite a lot of ground quite quickly in this article. The message I hope you take away from it is that dither—for all its wondrous ability to confer analog-like behavior on digitized signals—should be applied with care, particularly at the 16-bit level. In converting some 24-bit files to 16-bit it may be unnecessary to use dither, and the sound quality may benefit from its deletion. Where dither needs to be applied only fitfully, a contingent approach suggests itself. And dither noise might also be more effectively hidden where there is strong correlation between channels by using correlated rather than uncorrelated dither.
Although it is understandable, given typical levels of microphone self-noise, it is still disconcerting to find that many commercial audiophile 24-bit recordings achieve no better than 16-bit noise performance. The positive spin on this is that we may as yet not have exploited 24-bit to the full, particularly in purist recordings where the SPLs experienced at the microphones are relatively low. We've seen multidriver arrays being applied to loudspeaker design; perhaps multicapsule microphone arrays are what are now needed to make the most of the dynamic range available via 24-bit recording.
We've seen that most of the 24-bit recordings I've analyzed can be truncated to 16-bit sans dither without this introducing many—sometimes any—signal-correlated quantization errors that are detectable either by listening to the quantization error or by applying the lag 1 autocorrelation test. Choosing not to dither such recordings when converting them to 16-bit can be justified on pure engineering grounds because it can never be good practice to unnecessarily compromise signal/noise ratio. But I suspect most audio professionals would rather play safe and add dither, in the knowledge that the degradation in noise performance is quite small and in the expectation that it will pass unnoticed. But what if the addition of unnecessary dither actually compromises sound quality? This is not so left-field a notion as it may seem. There is no question that noise at this level is audible, or that it can influence sound quality. To appreciate this, you have only to note the development of noise-shaped dither and the strongly held preferences for different noise-shaping algorithms among recording and mastering engineers. Some even eschew all noise-shaped dithers, preferring instead the flat-spectrum alternative. Still, it is a surprise to find that such small changes in noise floor are audible even when flat-spectrum TPDF dither is added to signals that already have a noise floor of higher amplitude.
Fig.6 How summing the outputs of different numbers of independent random-number generators can be used to create noise with different probability density functions. A single random-number generator produces rectangular probability density function (RPDF) noise (black trace). Combining two random-number generators produces triangular probability density function (TPDF) noise (red). As the number of random-number generators increases, the PDF noise becomes more like that of Gaussian analog noise.
The first thing you notice when comparing the piano tracks with the different noise signatures—again with the original as a reference—is that TPDF noise is more irritating than the more Gaussian-like alternatives. And it has an effect on the sound of the piano, which is more "clangy" than in the original, or in those tracks with a more natural noise PDF. Of course, this experiment was conducted with an amplitude of noise getting on toward 30dB higher than 16-bit TPDF dither, but it may be that even at this much lower amplitude, and even when the dither is added to more naturally distributed noise, the ear can still detect it as something unnatural.
Thinking along these lines, I have also experimented with how best to "hide" TPDF dither within a typical audio signal. It is normal practice in two-channel or multichannel recordings to use uncorrelated dither in each channel. This has the advantage that summing two uncorrelated noise signals increases the noise amplitude by 3dB, whereas summing two correlated noise signals increases the amplitude by 6dB. So uncorrelated dither promises a superior S/N ratio in normal listening, and if the channels are summed to mono or a multichannel signal is downmixed to stereo.
I've covered quite a lot of ground quite quickly in this article. The message I hope you take away from it is that dither—for all its wondrous ability to confer analog-like behavior on digitized signals—should be applied with care, particularly at the 16-bit level. In converting some 24-bit files to 16-bit it may be unnecessary to use dither, and the sound quality may benefit from its deletion. Where dither needs to be applied only fitfully, a contingent approach suggests itself. And dither noise might also be more effectively hidden where there is strong correlation between channels by using correlated rather than uncorrelated dither.















