| Columns Retired Columns & Blogs |
Blind Listening Page 3
The splitter box fed both power amplifiers via 1m lengths of Monster M1000 and the output levels of the two amplifiers were matched at 1kHz by reducing the input to the VTLs. A debate ensued in some of the sessions as to whether it would have been better to have used wide-band noise to determine the level matching. I decided against this mainly because of the impracticality—noise naturally results in a constantly changing reading on the meter unless a large time-constant is contrived. I must admit to some puzzlement, however, when told by one member of the audience that this method was invalid and that I should have matched the acoustic levels with a sound-level meter. I may be missing something here, but if the output voltage at 1kHz of each amplifier is the same and they drive the same loudspeakers via the same cables, the acoustic levels at 1kHz will also be identical. Won't they? I also ensured that the volume level was a constant for each piece of music throughout the weekend's testing and that neither of the amplifiers was driven anywhere near clipping. (In fact I was surprised by the small power levels used, presumably because the room was so live, even when full of people.)
Footnote 6: For many years the co-producer and co-presenter of Peter Sutheim's "In-Fidelity" program in Los Angeles (Radio KPFK, 90.7 FM, Sundays at noon). Will's professional career is in biomedical research, with a heavy involvement in controlled clinical trials.
In previous published tests using double-pole, double-throw switches or relays, there had been much debate over the fact that the switching arrangements could themselves obscure subjective differences between the amplifiers. I decided upon a technique whereby all the changeover switching would be done by physically plugging and unplugging the speaker leads, thus ensuring a clean metal-metal contact every time. The Adcom and each of the VTL monoblocks was therefore connected to an array of five-way binding posts via 4' lengths of Mission multistrand cable (chosen because of its flexibility) terminated with dual banana plugs. Each channel of each power amplifier could be plugged either into a pair of binding posts feeding a loudspeaker or into a pair that fed a dummy 10 ohm resistive load, thus ensuring that at no time would an amplifier's output not be loaded down. (This is particularly important in the case of the tube amplifier, with its transformer-coupled output stage.)
A curtain screened the amplifiers and operator from the listeners—the plugging and unplugging was in the capable hands of Will Hammond for seven of the eight sessions and Robert Harley for the other session—and to ensure that there were no false clues, Will and Robert unplugged and plugged both channels of both amplifiers for every comparison, whether it was the same or not.
The B&W 801s were bi-wired from the binding-post matrix with 15' lengths of AudioQuest LiveWire Clear speaker cable, this a low-impedance, multi-solid-core design. Why bi-wire, when the connection from the amplifiers to the binding posts was single-wired? First, I wanted to keep the overall cable impedance as low as possible; second, as the speakers were internally set up for bi-wiring, why not?
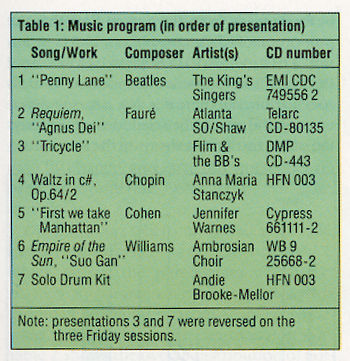
The choice of music for a blind test is far from trivial—as one listener said at the time, "You have to care whether there is a difference or not." In the event, with each of the eight sessions scheduled to last an hour and featuring around 60 listeners, I felt we would have sufficient data-gathering opportunity to investigate whether the music itself had an effect. I therefore chose seven diverse recordings—multimiked, multitrack vocal, simply miked choir and orchestra, electronic fusion "audiophile" music, solo piano, modern rock, boy treble and organ, coincident-miked solo drums—so that we could see if there was any correlation between the type of music and the success with which it enabled listeners to identify any difference between the amplifiers. (It would have given me great satisfaction, for example, if a rock track had proved as efficacious as classical—see J. Gordon Holt's comments in his letter in this issue!) The seven pieces are shown in Table 1 and, with three exceptions, were presented in the same order for each session. The exceptions were in the Friday sessions, where the Tricycle and drum tracks were transposed, so that Will could see if this by itself would produce any difference in the scoring.
Each session therefore went as follows: after everyone was seated and suffered an introductory talk by yours truly, they were presented with nine presentations, each consisting of a piece of music repeated. The first two trials were for learning purposes—it would be folly indeed to go straight into a blind test with every listener unfamiliar with the room, the system, and the music—and I identified each amplifier for the listeners with both pieces of music, first the drum track from the HFN/RR Test CD, then "Penny Lane" from the King's Singers Beatles album. The seven blind presentations then followed, with each piece of music lasting some 90 seconds or so. I made "Penny Lane" the first blind trial on purpose. I wanted to see if the fact that a blind test immediately followed a sighted comparison with the same piece of music affected the scoring in any way. At the end of the session, the listeners were instructed to exchange score sheets with their neighbors and mark the answers as correct or not. The sheets were then collected up for Will Hammond to analyze at his leisure.
The test was, of course, single-blind, in that the operator knew which amplifier was being listened to at any time. He was out of the listeners' sight, however, and, as explained above, the changeover took the same time and the same amount of fuss whether the amplifiers were the same or different. Although I was in the listeners' view during the test, I had no idea what they were listening to apart from during the introductory learning sessions, and therefore could not be regarded as a source of clues.—JA
Will Hammond (footnote 6) analyzes the results
What we got out of this, for starters, were 3530 responses as to whether the amp was the same—Yes or No—from 505 listeners in 8 sessions (footnote 7). (I know, 505 x 7 = 3535, but 5 listeners only made 6 choices. That's OK.)
What we did not find out about the listeners were: 1) their ages, although it seemed mostly a middle-aged (30-50) lot; 2) whether male or female (there was a pleasantly and surprisingly high number of females there); 3) the level of their auditory acuity; 4) the level of analytical skills they had and the extent of their prior experience in comparative evaluation; and 5) their particular tastes in music. The levels of interest and responsible participation were certainly quite high, else they wouldn't have waited in lines in a crowded hallway to get in, nor would they have readily handed in marked score sheets (often with their names on them) that indicated audibly disappointing performance on the tests.
Once all the responses were analyzed, what did we find out? Most strikingly, that the inter-session variation in proportion of correct responses was considerable. Assuming (correctly) that one could get 50±7% correct just by guessing all "Same" or all "Different" answers, we considered those who got either 3 or 4 correct out of 7 possible to be the middle group (the largest). Those who only got 2 or less correct were the unskilled ones, while getting 5 or more correct put the listener in the Keen-Eared Observer, or KEO, group. Fig.1 shows the overall results, with the percentage of each group of listeners for each session getting 0, 1, 2, 3, 4, 5, 6, or 7 identifications correct presented in bargraph form.
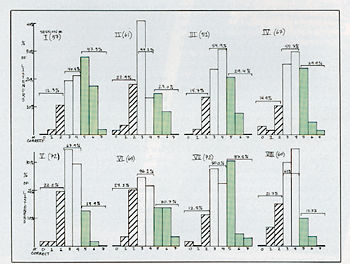
Fig.1 Session-by-session scoring
Footnote 6: For many years the co-producer and co-presenter of Peter Sutheim's "In-Fidelity" program in Los Angeles (Radio KPFK, 90.7 FM, Sundays at noon). Will's professional career is in biomedical research, with a heavy involvement in controlled clinical trials.
Footnote 7: Assuming a Normal distribution for the data gives a probability of just over 0.1% that this result was due to chance; ie, if you were tossing a coin 3530 times, the probability that you would throw 1846 heads would be a little less than one in 1000. The Chi-Squared test, assuming one degree of freedom, also indicates that the chances of the listeners achieving this overall score purely by chance are somewhere between 1% and 0.1%. The conclusion to be drawn is that it is largely probable that there is a real, if small under the test conditions, audible difference between the Adcom and the VTL amplifiers.—JA
NEXT: Page 4 »
|
| |||||||||
- Log in or register to post comments

































| Loudspeakers Amplification Digital Sources | Analog Sources Accessories Featured | Music Columns Retired Columns | Show Reports | Features Latest News Community | Resources Subscriptions |
 © 2024 Stereophile
© 2024 StereophileAVTech Media Americas Inc., USA
All rights reserved

